링크: https://arxiv.org/abs/1812.04948
저널|학회: CVPR 2019
연구목적: ProGAN의 개선, Disentanglment 개선
데이터셋: N/A
주요결과: 고해상도 이미지 생성, FFHQ 데이터셋, Disentanglement
저자: Tero Karras et al.
1. Introduction
StyleGAN으로 알려진 이 논문은 Progressive Growing의 아이디어와 함께 Style transfer의 아키텍처로 부터 영감을 받아 혁신적인 Generator를 고안하였다. 논문에서 제안된 style-based generator만으로 기본적인 discriminator나 loss에도 robust하다. 이 논문 이후로 StyleGAN의 여러 버전이나오고 있으나 전반적인 연구 흐름을 따라가기 위해 이해하고 넘어가면 좋을 것같다. 본 연구의 주요 Contribution은 다음과 같다.
- style-based Generator로 고해상도, 고퀄리티 이미지를 생성한다.
- 기존 GAN구조의 entanglement할 수밖에 없음을 재확인하였다.
- Disentanglemen를 재정의 하고 좋은 퀄리티의 이미지를 생성하는 것에 초점을 둔다.
- FFHQ데이터셋을 제시한다.
2. Style-based Generator
StyleGAN은 앞서 말한 바와 같이 Generator의 아키텍처에 초점을 두고 있다. 이 구조에서 주목할만한 부분은 다음과 같다.
- Mapping Network
- AdaIN
- Noise Injection
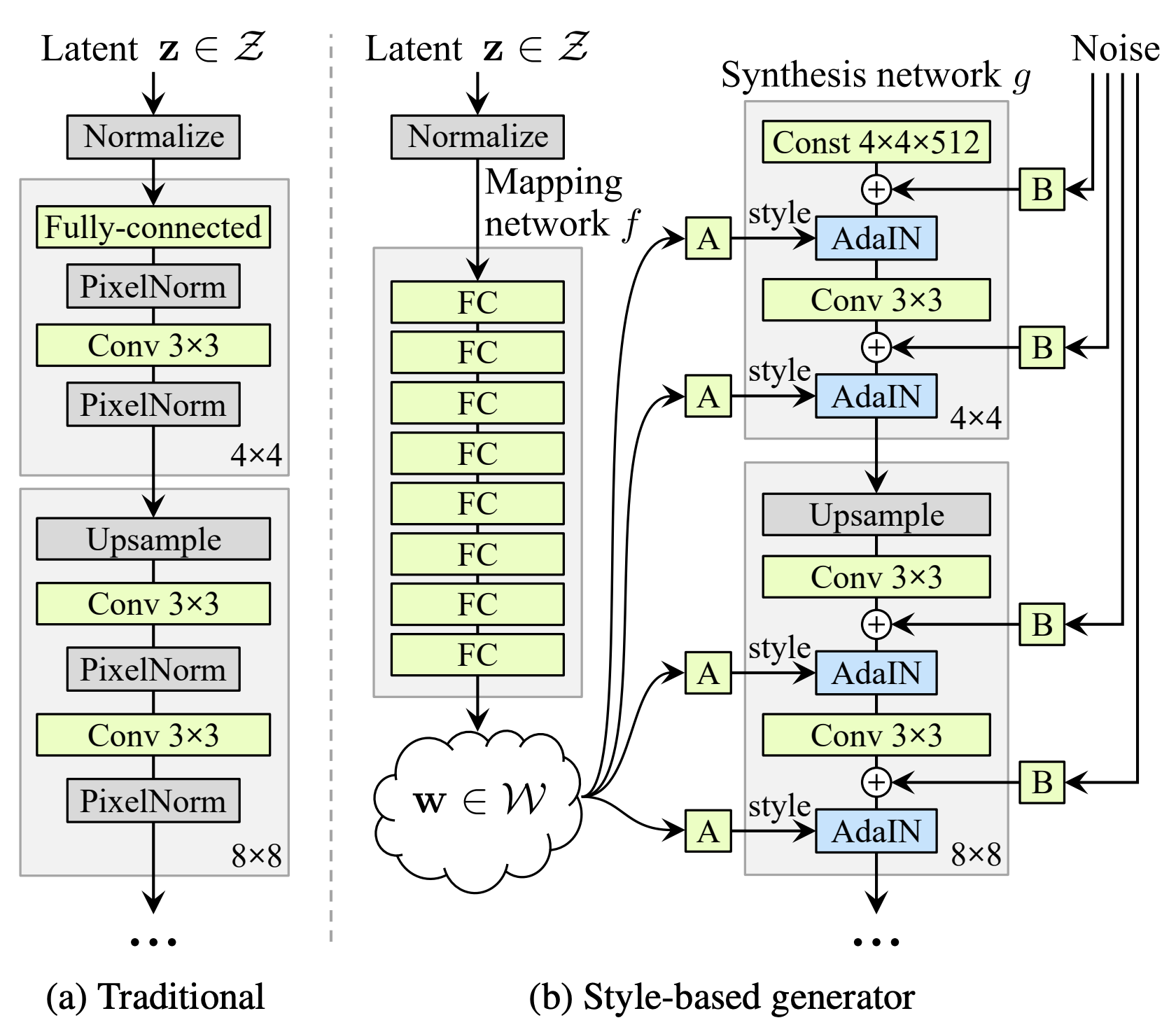
Fig. 1. baseline과 styleGAN 아키텍처 비교
2.1 Mapping Network
Mapping Network의 경우 Mapping Network을 이해하기 위해 먼저 disentanglement가 무엇인지 알아야할 필요가 있다.
Entanglement를 직역하면 ‘얽혀있다’라는 의미로, 반대로 Disentanglement는 ‘잘 분리되어있다’ 정도로 해석할 수 잇다. GAN에서는 1) 어떤 attribute를 잘 나눌수 있다는 것, 2)latent space가 linear subspace로 구성된다는 것을 의미한다.
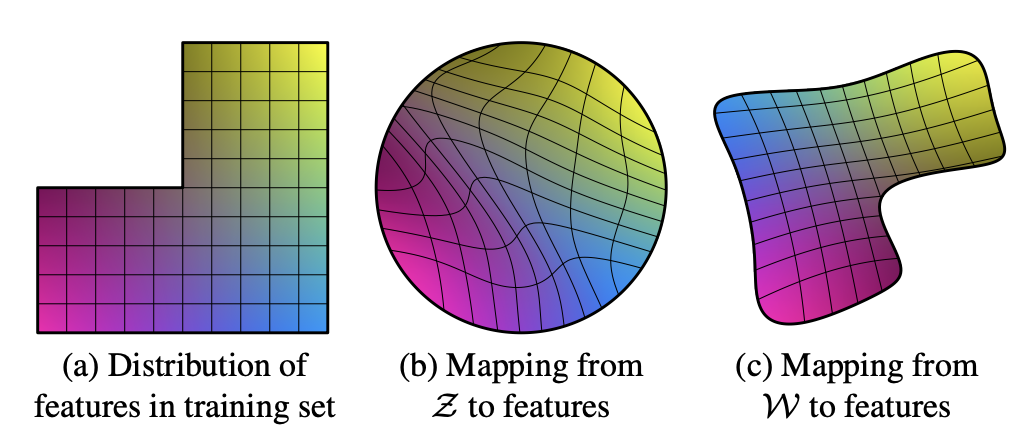
Fig. 2. Entanglement의 시각적 설명
Fig. 2a를 실제 데이터의 분포라고 하고 가로축은 성별, 세로축은 머리길이에 대한 축이라고 할때, 머리가 짧은 남성에서 머리가 긴 여성으로 interpolation을 수행한다면, Fig. 2a와 같이 중간 과정의 데이터셋이 존재 하지 않는다고 가정할때 interpolation 중간에 급격한 변화(성별과 머리길이에 상관없는 feature)가 나타난다. 이를 space가 linear하지 않다는 것을 의미한다.
Fig. 2b는 PGGAN의 경우로 데이터 분포를 Gaussian으로 가정하기 때문에
Fig. 2c는 entanglment를 방지하기 위해 mapping network를 통해
mapping network를 통해 smpling한
2.3 AdaIN
AdaIN (Adaptive Instance Normalization)은 Style Transfer에 사용되는 기술로, 콘텐츠 이미지에 스타일 이미지의 특성을 적용하는 데 사용된다. 이 과정은 다음과 같은 단계로 구성된다:
- 콘텐츠 이미지의 정규화: 콘텐츠 이미지 x는 인스턴스 정규화를 통해 정규화됩니다. 이는 각 이미지(인스턴스)와 채널별로 평균을 0으로, 분산을 1로 조정하는 과정입니다. 여기서
는 의 평균, 는 의 표준편차이다.
스타일 이미지의 Affine 변환: 스타일 이미지
는 Affine 변환을 통해 스타일 스케일링 인자 와 스타일 바이어스 인자 를 생성한다. 이 변환은 신경망을 통해 학습되며, 스타일 이미지의 특징을 캡처하는 데 사용된다. 정규화된 콘텐츠 이미지
는 스타일 이미지에서 추출된 스케일링 인자와 바이어스 인자를 사용하여 조정된다. 이는 콘텐츠 이미지에 스타일 특성을 입히는 과정이다.
AdaIN은 Instance Normalization을 기반으로 하며, 각 인스턴스와 채널별로 스타일 인자들이 적용된다. 이를 통해 콘텐츠 이미지는 원래의 구조를 유지하면서 스타일 이미지의 특성을 획득한다. 학습 가능한 Affine 변환은 스타일 이미지로부터 복잡한 스타일 특징을 추출하고, 이를 콘텐츠 이미지에 효과적으로 적용할 수 있게 한다. 이 과정은 신경망을 통해 자동으로 이루어지며, 다양한 스타일의 이미지에 대해 유연하게 적용될 수 있다.
Fig. 1b에서 AdaIN에 주어지는 style은
2.4 Constant Input
style-based generator는 w를 입력으로 받기 때문에, 더이상 PGGAN이나 다른 GAN과 같이 z에서 convolution연산을 하지 않아도 된다. 때문에 synthesis network는 4x4x512 contant tensor에서 부터 시작한다.
기존처럼 randome noise에서부터 바로 네트워크를 통해 이미지를 생성하는것은 비교적으로 학습하기 어려워, 학습된 초기 4x4영상의 constant를 사용하면 더 쉽게 수렴할 수 있다.
2.5 Noise Injection (Stochastic Variation)

Fig. 3. Results of Noise Injection
생성된 이미지가 사실적이면서도 다채로운(다양한) 이미미지를 생성하기 위해 특정 noise를 주입한다. 이 noise는 예를들어 사람 얼굴에서 머리카락이나 수염, 모공등과 같이 stochastic한 특성을 가지는 부분들이 다양하게 나타날 수 있도록 다양성을 증대시키는데 도움을 준다. Fig. 1b의
Fig. 3b, Fig.3c와 같이 Fiig. 3a이미지에 대해 다양한 noise를 주입한 결과로 높은 다양성을 가지는것을 확인할 수 있다.
3. Disentanglement Measure
추후 업데이트 예정입니다.
")